Large Language Models, Myths and Realities
Everything you wanted to know about Deep Learning and Large Language Models but were afraid to ask
2025-10-06
Generalities on Machine Learning and Artificial Intelligence
Historical perspective on AI
AI was all about symbolic reasoning until the 1980s: culmination in “Expert Systems”, which are abandoned:
- 🧱 based on a fixed and very hard to improve set of rules
- 💥 fails miserably in “edge” case and with outliers’ data
- 🧑🔬 relies on a bunch of expert domains and general reliability is very hard to assess
\Rightarrow 🧠 an alternative neuro-computing branch of AI, but…
… in mid ’80s they seem to have both failed to deliver on their promises. 🤷♂️
Historical perspective timeline
- 1950s: perceptron (Rosenblatt 1958)
- 1960s: perceptron convergence theorem (Minsky and Papert 1969)
- 1970s-1980s: backpropagation (Rumelhart, Hinton, and Williams 1986)
- 1990s: SVM (Cortes and Vapnik 1995)
- 2000s: Boosting (Freund and Schapire 1997), Random Forests (Breiman 2001)
- 2010s: Deep Learning (Goodfellow, Bengio, and Courville 2016)


AI domains
Artificial Intelligence (AI)
Machine Learning (ML)
Deep Learning (DL)
Large Language Models (LLM)
Train a neural network

- Class of prediction functions f_\theta: linear, quadratic, trees
- Loss \mathcal{L}: L^2 norm, CrossEntropy, purity score
- Optimizer: SGD, Adam, …
- learning rate \eta: \theta_{k+1} \gets \theta_k - \eta \nabla_\theta \mathcal{L}
- other hyperparameters
- Dataset:
- training: \{(x_i, y_i)\}_{i} to compute loss between prediction f_{\theta}(x_i) and label y_i to update \theta
- test: only compute performance scores (no more updates !)
A quick survey of Deep Learning
Foreword, beware the Alchemy
![]()
📜 More or less theoretical guarantees
- 🧑🔬 field of research
- 🧠 type of network
- 🔬 from theory to applications: a gap
🛠️ Myriad of ad-hoc choices, engineering tricks and empirical observations
🚦 Current choices are critical for success: what are their pros and cons?
🔄 Try ➔ ❌ Fail ➔ 🔁 Try again is the current pipeline
Science and/or Alchemy?
![]()
- 🤔 Criticable current state of Deep Learning research,
- ⚠️ lack of scientific rigor in the field.
![]()
- arguing that mathematical rigor is not critical in Deep Learning research 🤷♂️
- the field is doing just fine without it. 🚀
Criticizing an entire community (and an incredibly successful one at that) for practicing “alchemy” 🧪, simply because our current theoretical tools haven’t caught up with our practice is dangerous. Why dangerous? It’s exactly this kind of attitude that led the ML community to abandon neural nets for over 10 years, despite ample empirical evidence that they worked very well in many situations. (Yann LeCun, 2017, My take on Ali Rahimi’s “Test of Time” award talk at NIPS.)
The main ingredients
- 🧮 Tensor algebra (linear algebra)
- 🔁 Automatic differentiation
- 🏃♂️ (Stochastic) Gradient descent
- 🛠️ Optimizers
- ⚡ Non-linearities
- 📦 Large datasets
Also, on hardware side:
- 🖥️ GPU
- 🌐 Distributed computing
![]()
shape=(batch, height, width, features)
Tensor algebra
- Linear algebra operations on tensors
- MultiLayerPerceptron = sequence of linear operations and non-linear activations
f(x)=\phi_{L}\!\Big(W_{L}\,\phi_{L-1}\big(W_{L-1}\,\cdots \phi_{1}(W_{1}x+b_{1})\cdots + b_{L-1}\big)+ b_{L}\Big)
\Rightarrow input can be anything: images, videos, text, sound, …
x = \mathrm{vec}\!\Big( \underbrace{T_{\text{img}}}_{\in \mathbb{R}^{H\times W\times C}} \;\Vert\; \underbrace{T_{\text{text}}}_{\in \mathbb{R}^{L\times d_w}} \;\Vert\; \underbrace{T_{\text{audio}}}_{\in \mathbb{R}^{T\times d_a}} \;\Vert\; \underbrace{T_{\text{video}}}_{\in \mathbb{R}^{F\times H'\times W'\times C'}} \Big)
Automatic differentiation
- 🔗 Chain rule to compute gradient with respect to \theta
- 🗝️ Key tool: backpropagation
- 🧠 Don’t need to store the computation graph entirely
- ⚡ Gradient is fast to compute (a single pass)
- 🧮 But memory intensive
f(x)=\nabla\frac{x_{1}x_{2} sin(x_3) +e^{x_{1}x_{2}}}{x_3}
![]()
\begin{darray}{rcl} x_4 & = & x_{1}x_{2}, \\ x_5 & = & sin(x_3), \\ x_6 & = & e^{x_4}, \\ x_7 & = & x_{4}x_{5}, \\ x_8 & = & x_{6}+x_7, \\ x_9 & = & x_{8}/x_3. \end{darray}
Gradient descent
Example with a non-convex function f(x_1, x_2) = (x_1^2 + x_2 - 11)^2 + (x_1 + x_2^2 - 7)^2
minX = -5;
maxX = 5;
f = ([x1, x2]) => (x1**2 + x2 - 11)**2 + (x1 + x2**2 - 7)**2;
{
const linspace = d3.scaleLinear().domain([0, 49]).range([minX, maxX]);
const X1 = Array.from({length: 50}, (_, i) => linspace(i));
const X2 = Array.from({length: 50}, (_, i) => linspace(i));
// Define your function f here
const f = ([x1, x2]) => (x1**2 + x2 - 11)**2 + (x1 + x2**2 - 7)**2;
const Z = X1.map((x1,i) => X2.map((x2,j) => f([x1,x2])));
const data = [{
x: X1.flat(),
y: X2.flat(),
z: Z,
type: 'surface',
showscale: false
}];
const layout = {
autosize: false,
width: 400,
height: 400,
paper_bgcolor: "rgba(0,0,0,0)",
plot_bgcolor: "rgba(0,0,0,0)",
template: 'plotly_dark',
margin: {
l: 65,
r: 50,
b: 65,
t: 90,
}
};
const div = document.createElement('div');
Plotly.newPlot(div, data, layout,{displayModeBar: false});
return div;
}
function grad_descent(x1,x2,step,max_iter) {
let grad = f_grad(x1, x2);
let iterations = [[x1, x2]];
function f_grad(x1, x2) {
let df_x1 = 2 * (-7 + x1 + x2**2 + 2 * x1 * (-11 + x1**2 + x2));
let df_x2 = 2 * (-11 + x1**2 + x2 + 2 * x2 * (-7 + x1 + x2**2));
return [df_x1, df_x2];
}
var count = 0;
while (count < max_iter) {
x1 -= step * grad[0];
x2 -= step * grad[1];
grad = f_grad(x1, x2);
if (isFinite(x1) && isFinite(x2) &&
(minX < x1) && (x1 < maxX) &&
(minX < x2) && (x2 < maxX))
iterations.push([x1, x2]);
else iterations.push(iterations[count])
count += 1
}
return iterations;
}
viewof descent_params = Inputs.form({
x1: Inputs.range([minX, maxX], {step: 0.1, value: 0, label: 'x1'}),
x2: Inputs.range([minX, maxX], {step: 0.1, value: 0, label: 'x2'}),
step: Inputs.range([0.001, 0.04], {step: 0.001, value: 0.01, label: 'step_size'})
})
{
var iterations = grad_descent(descent_params.x1,descent_params.x2,descent_params.step,20)
return Plot.plot({
aspectRatio: 1,
x: {tickSpacing: 50, label: "x1 →"},
y: {tickSpacing: 50, label: "x2 →"},
width: 320,
style: {
backgroundColor: 'rgba(0,0,0,0)'
},
marks: [
Plot.contour({
fill: (x1, x2) => Math.sqrt((x1**2 + x2 - 11)**2 + (x1 + x2**2 - 7)**2),
x1: minX,
y1: minX,
x2: maxX,
y2: maxX,
showlegend: false,
colorscale: 'RdBu',
ncontours: 30
}),
Plot.line(iterations,{marker: true})
]
})
}Sensitivity to initial point and step size
(Stochastic) Gradient descent
- 🚫 not use all the data at once to compute the gradient
- 🧠 not feasible in practice (memory wise)
- 🗂️ Use mini-batch of data (bootstrap samples)
- ⚙️ one more hyperparameter…
\theta_{k+1} \leftarrow \theta_k - \frac{\eta}{n}\sum_{i\in\text{batch}}\nabla_\theta \mathcal{L}(f_\theta(x_i), y_i)
\Rightarrow 🚫 No general guarantees of convergence in DL setting
Optimizers
SGD, Adam, RMSProp
- 🔬 Non-convex optimization research on the subject is still very active, and there is no clear consensus on what is the best optimizer to use in a given situation.
- ❌ No guarantee of global minimum, only local minimum
- ⚠️ No guarantee of convergence, only convergence in probability
(More than) a pinch of non-linearities
- 🔀 Linear Transformations + ⚡ Non-linear activation functions
- 🚀 Radically enhance the expressive power of the model
- 🧭 Ability to explore the space of functions in gradient descent.

Train a Large Language Model (LLM)
From text to numbers
- 🧮 Main problem: we can’t multiply or do convolutions with words
- 📚 Second problem: many words (for a single language)
- 🧠 Third problem: how to capture semantics?
Embeddings
- Distance between words should not be character based
women
woman
window
widow
Tanguy Lefort, 2023
Embeddings
- Distance between words should not be character based
widow
women
woman
window
Tanguy Lefort, 2023
Multi-scale learning from text
- 🏗️ DL layers = capture different levels of dependencies in the data
- 👀 attention mechanism applies “multi-scale learning” to data sequences \Rightarrow 🧩 e.g. not only words in sentences, but sentences in paragraphs, paragraphs in documents and so on.
\Rightarrow 🤖 transformers capture dependencies in the “whole” 🧩

Multi-facets learning from text
🧠 the attention mechanism extends to multifaceted dependencies of the same text components.
In the sentence :
the cat sat on the rug, and after a few hours, it moved to the mat.
\Rightarrow All those groups of words/tokens are multiple facets of the same text and its meaning. 🌈🔍

Transformers

Vaswani et al. (2017)
Heart of Transformers: Attention mechanism
\text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
- Three matrices: Query, Key, Value, derived from the input sequence
- d_k: dimension of the key matrix, typically 64 or 128
- weighted sum of the values V ~ compatibility between the query and the keys
- softmax to get a probability distribution
- multi-head attention: several attention mechanisms in parallel

Vaswani et al. (2017)
Head view of attention
- Each line shows the attention from one token (left) to another (right).
- Line weight reflects the attention value (ranges from 0 to 1),
- line color identifies the attention head
BERT: Bidirectional Encoder Representations from Transformers
- embeddings: represent words as vectors in high dimensions

Checking and loading models
mutable embeddingPipeline = null
mutable gptTokenizerInstance = null
mutable gptModelInstance = null
mutable modelLoadState = ({
status: "idle",
webgpu: false,
ready: false,
error: null
})
mutable loadTrigger = 0
// Load button
viewof loadModelsButton = {
const supportsWebGPU = typeof navigator !== "undefined" && !!navigator.gpu;
if (!supportsWebGPU) {
return html`<div style="color: #d4d4d4; font-size: 0.85em;">❌ WebGPU is not available in this browser.</div>`;
}
const button = html`<button style="
background-color: #007bff;
color: white;
border: none;
padding: 10px 20px;
border-radius: 4px;
font-size: 0.9em;
cursor: pointer;
transition: background-color 0.2s;
" ${modelLoadState.status === "loading" || modelLoadState.status === "ready" ? "disabled" : ""}>
${modelLoadState.status === "ready" ? "✅ Models Loaded" :
modelLoadState.status === "loading" ? "⏳ Loading..." :
"🚀 Load Models (~1.2GB)"}
</button>`;
button.onmouseover = () => {
if (modelLoadState.status !== "loading" && modelLoadState.status !== "ready") {
button.style.backgroundColor = "#0056b3";
}
};
button.onmouseout = () => {
button.style.backgroundColor = "#007bff";
};
button.onclick = () => {
if (modelLoadState.status !== "loading" && modelLoadState.status !== "ready") {
mutable loadTrigger = loadTrigger + 1;
}
};
return button;
}
modelLoader = {
// Wait for button click
if (loadTrigger === 0) {
return html`<div style="color: #888; font-size: 0.85em;">Click the button above to load models.</div>`;
}
const supportsWebGPU = typeof navigator !== "undefined" && !!navigator.gpu;
const container = html`<div style="display: flex; flex-direction: column; gap: 12px;">
<div style="color: #d4d4d4; font-size: 0.85em;"></div>
</div>`;
const statusLine = container.firstElementChild;
mutable modelLoadState = {
status: supportsWebGPU ? "loading" : "unsupported",
webgpu: supportsWebGPU,
ready: false,
error: null
};
if (!supportsWebGPU) {
statusLine.textContent = "❌ WebGPU is not available in this browser. The interactive demos require a WebGPU-capable environment.";
return container;
}
statusLine.textContent = "🔍 WebGPU detected. Loading models...";
const steps = [
{ key: "embedding", label: "Embedding model (feature extraction)" },
{ key: "tokenizer", label: "Qwen3 tokenizer" },
{ key: "model", label: "Qwen3 causal language model" }
];
const stepMap = new Map();
for (const step of steps) {
const row = document.createElement("div");
row.style.display = "flex";
row.style.flexDirection = "column";
row.style.gap = "4px";
const label = document.createElement("div");
label.textContent = step.label;
label.style.color = "#d4d4d4";
label.style.fontSize = "0.75em";
const bar = document.createElement("div");
bar.style.height = "8px";
bar.style.width = "100%";
bar.style.background = "#3e3e3e";
bar.style.borderRadius = "999px";
const fill = document.createElement("div");
fill.style.height = "100%";
fill.style.width = "0%";
fill.style.background = "#79d2ff";
fill.style.borderRadius = "999px";
fill.style.transition = "width 0.3s ease";
bar.appendChild(fill);
row.appendChild(label);
row.appendChild(bar);
container.appendChild(row);
stepMap.set(step.key, { label, fill, baseLabel: step.label });
}
const setProgress = (key, percentage, note = "") => {
const step = stepMap.get(key);
if (!step) return;
const { fill, label, baseLabel } = step;
label.textContent = note ? `${baseLabel} — ${note}` : baseLabel;
fill.style.width = `${Math.min(100, Math.max(0, percentage))}%`;
if (percentage >= 100) {
fill.style.background = "#3fb618";
} else if (percentage > 0) {
fill.style.background = "#79d2ff";
}
};
const setError = (key) => {
const step = stepMap.get(key);
if (!step) return;
const { fill } = step;
fill.style.width = "100%";
fill.style.background = "#ff6b6b";
};
// Track progress items exactly like the official qwen3-webgpu example
// Each model tracks its own array of progress items (files currently downloading)
const progressItemsMap = new Map(); // Map<key, Array<progressItem>>
const hasSeenLargeFileMap = new Map(); // Map<key, boolean> - track if we've seen a large file for this model
const formatBytes = (size) => {
const i = size === 0 ? 0 : Math.floor(Math.log(size) / Math.log(1024));
return (
(size / Math.pow(1024, i)).toFixed(2) * 1 +
["B", "kB", "MB", "GB", "TB"][i]
);
};
const updateProgressDisplay = (key) => {
const items = progressItemsMap.get(key) || [];
const step = stepMap.get(key);
if (!step) return;
const { fill, label, baseLabel } = step;
// If no items, show complete
if (items.length === 0) {
label.textContent = `${baseLabel} — ready`;
fill.style.width = "100%";
fill.style.background = "#3fb618";
return;
}
// Check if we have or have ever seen a large file for this model
let hasLargeFile = hasSeenLargeFileMap.get(key) || false;
items.forEach(item => {
// Check if we have any large files (> 10MB) - these are the main model files
if (item.total && item.total > 10 * 1024 * 1024) {
hasLargeFile = true;
hasSeenLargeFileMap.set(key, true);
}
});
// If we haven't seen a large file yet, show 0% "preparing..."
// This prevents showing progress on small config files before the big model downloads
if (!hasLargeFile) {
label.textContent = `${baseLabel} — preparing...`;
fill.style.width = "0%";
return;
}
// Calculate average progress across all active files (official example pattern)
let totalProgress = 0;
items.forEach(item => {
totalProgress += (item.progress || 0);
});
const percentage = items.length > 0 ? (totalProgress / items.length) : 0;
fill.style.width = `${Math.min(100, percentage)}%`;
fill.style.background = percentage >= 100 ? "#3fb618" : "#79d2ff";
// Show details of the last active file
const lastItem = items[items.length - 1];
const fileName = lastItem.file.split('/').pop();
const loadedSize = lastItem.loaded ? formatBytes(lastItem.loaded) : "0B";
const totalSize = lastItem.total ? formatBytes(lastItem.total) : "?";
label.textContent = `${baseLabel} — ${fileName} (${loadedSize}/${totalSize})`;
};
const createProgressCallback = (key) => {
return (data) => {
// Only log important events, not every progress update
if (data.status !== "progress") {
console.log(`[${key}] ${data.status}:`, data.file?.split('/').pop());
}
const items = progressItemsMap.get(key) || [];
switch (data.status) {
case "initiate":
// Add new progress item to the list (official pattern)
progressItemsMap.set(key, [...items, data]);
updateProgressDisplay(key);
break;
case "progress":
// Update existing progress item (official pattern)
progressItemsMap.set(key,
items.map((item) => {
if (item.file === data.file) {
return { ...item, ...data };
}
return item;
})
);
updateProgressDisplay(key);
break;
case "done":
// Remove completed item from the list (official pattern)
progressItemsMap.set(key,
items.filter((item) => item.file !== data.file)
);
updateProgressDisplay(key);
break;
}
};
};
(async () => {
try {
// Load models SEQUENTIALLY (not in parallel) to avoid progress tracking issues
// This matches how the official qwen3-webgpu example works
if (!embeddingPipeline) {
setProgress("embedding", 0, "starting download...");
const result = await pipeline(
"feature-extraction",
"onnx-community/Qwen3-Embedding-0.6B-ONNX",
{
device: "webgpu",
dtype: "q4f16",
progress_callback: createProgressCallback("embedding")
}
);
mutable embeddingPipeline = result;
// Explicitly set to 100% when complete
const embeddingStep = stepMap.get("embedding");
if (embeddingStep) {
embeddingStep.fill.style.width = "100%";
embeddingStep.fill.style.background = "#3fb618";
embeddingStep.label.textContent = `${embeddingStep.baseLabel} — ready`;
}
} else {
setProgress("embedding", 100, "already loaded");
}
if (!gptTokenizerInstance) {
setProgress("tokenizer", 0, "starting download...");
const result = await transformers.AutoTokenizer.from_pretrained(
"onnx-community/Qwen3-0.6B-ONNX",
{
progress_callback: createProgressCallback("tokenizer")
}
);
mutable gptTokenizerInstance = result;
// Explicitly set to 100% when complete
const tokenizerStep = stepMap.get("tokenizer");
if (tokenizerStep) {
tokenizerStep.fill.style.width = "100%";
tokenizerStep.fill.style.background = "#3fb618";
tokenizerStep.label.textContent = `${tokenizerStep.baseLabel} — ready`;
}
} else {
setProgress("tokenizer", 100, "already loaded");
}
if (!gptModelInstance) {
setProgress("model", 0, "starting download...");
const result = await transformers.AutoModelForCausalLM.from_pretrained(
"onnx-community/Qwen3-0.6B-ONNX",
{
device: "webgpu",
dtype: "q4f16",
progress_callback: createProgressCallback("model")
}
);
mutable gptModelInstance = result;
// Explicitly set to 100% when complete
const modelStep = stepMap.get("model");
if (modelStep) {
modelStep.fill.style.width = "100%";
modelStep.fill.style.background = "#3fb618";
modelStep.label.textContent = `${modelStep.baseLabel} — ready`;
}
} else {
setProgress("model", 100, "already loaded");
}
// All models loaded successfully
statusLine.textContent = "✅ Models loaded. You're ready to explore the demos.";
mutable modelLoadState = { status: "ready", webgpu: true, ready: true, error: null };
} catch (error) {
console.error("Model preload error:", error);
statusLine.textContent = `❌ Failed to load models: ${error.message}`;
setError("embedding");
setError("tokenizer");
setError("model");
mutable modelLoadState = { status: "error", webgpu: true, ready: false, error };
}
})();
return container;
}Demos are running entirely in the browser WebGPU (chrome, edge, firefox).
See Browser support for WebGPU for more details.
- Total download size: ~1.2GB (may take several minutes).
- Embedding model: typical size for an encoder.
- Decoder model: small for a generative model; limited text quality and more hallucinations due to less knowledge capacity.
- For comparison: GPT-5 is ~1.7TB (about 1000× larger).
BERT Demo
// Three separate interactive inputs with dark styling
viewof tasks = {
const cssText = 'background-color: #1e1e1e; color: #d4d4d4; border: 1px solid #3e3e3e; padding: 8px; border-radius: 4px; width: 100%;';
const task1 = Inputs.textarea({ label: "Text 1", rows: 2, value: "The questionnaire was not optimized for mobile devices." });
const task2 = Inputs.textarea({ label: "Text 2", rows: 2, value: "Please reduce the number of required fields." });
const task3 = Inputs.textarea({ label: "Text 3", rows: 2, value: "The weather is sunny today." });
const form = Inputs.form({
task1: task1,
task2: task2,
task3: task3
}, { columns: 1 });
return styleInput(form);
}
{
console.log("Transformers.js version:", transformers.env.version);
const data = similarities || [];
const table = Inputs.table(data, {
columns: ["pair","similarity"],
width: {pair: 160}
});
// Apply dark styling to the table
const tableEl = table.querySelector('table');
if (tableEl) {
tableEl.style.cssText = 'width: 100%; border-collapse: collapse; background-color: transparent;';
const thead = tableEl.querySelector('thead');
if (thead) {
thead.querySelectorAll('th').forEach(th => {
th.style.cssText = 'border: 1px solid #3e3e3e; font-weight: 600; background-color: #2d2d2d !important; color: #d4d4d4 !important;';
});
}
tableEl.querySelectorAll('tbody td').forEach(td => {
td.style.cssText = 'border: 1px solid #3e3e3e; background-color: #1e1e1e; color: #d4d4d4;';
});
tableEl.querySelectorAll('tbody tr').forEach(tr => {
tr.style.backgroundColor = 'transparent';
});
}
return table;
}// Debounce logic: watches inputs and updates mutable state after delay
debounceUpdate = {
const currentTexts = [tasks.task1.trim(), tasks.task2.trim(), tasks.task3.trim()];
const delay = 800; // 800ms delay
// Use Promises.delay to debounce
return Promises.delay(delay).then(() => {
mutable texts = currentTexts;
return html``;
});
}// Load feature-extraction pipeline with smaller, WebGPU-optimized model
similarityPipeline = {
if (embeddingPipeline) return embeddingPipeline;
while (!embeddingPipeline && modelLoadState.status !== 'error') {
await Promises.delay(200);
}
if (!embeddingPipeline) {
throw new Error(modelLoadState.error ? modelLoadState.error.message : 'Embedding pipeline unavailable');
}
return embeddingPipeline;
}// Compute similarities using the pipeline
similarities = {
if (!texts || texts.length < 3) return [];
// Get embeddings for all texts
const output = await similarityPipeline(texts, { pooling: 'mean', normalize: true });
// Use transformers.js util.cos_sim for similarity computation
const embeddings = [];
for (let i = 0; i < 3; i++) {
const start = i * output.dims[1];
const end = start + output.dims[1];
embeddings.push(output.data.slice(start, end));
}
// Compute cosine similarities (embeddings are normalized, so just dot product)
function cosineSimilarity(a, b) {
let sum = 0;
for (let i = 0; i < a.length; i++) {
sum += a[i] * b[i];
}
return sum;
}
return [
{ pair: "Text 1 ↔ Text 2", similarity: Math.round(cosineSimilarity(embeddings[0], embeddings[1]) * 1e4) / 1e4 },
{ pair: "Text 1 ↔ Text 3", similarity: Math.round(cosineSimilarity(embeddings[0], embeddings[2]) * 1e4) / 1e4 },
{ pair: "Text 2 ↔ Text 3", similarity: Math.round(cosineSimilarity(embeddings[1], embeddings[2]) * 1e4) / 1e4 }
];
}GPT : Generative Pre-trained Transformer
- autoregressive model
- generates text by predicting the next token
- pre-trained on large corpora of text

GPT Demo - Next Token Prediction
gptTokenizer = {
if (gptTokenizerInstance) return gptTokenizerInstance;
while (!gptTokenizerInstance && modelLoadState.status !== 'error') {
await Promises.delay(200);
}
if (!gptTokenizerInstance) {
throw new Error(modelLoadState.error ? modelLoadState.error.message : 'Tokenizer unavailable');
}
return gptTokenizerInstance;
}// Load GPT model and tokenizer (using preloaded Qwen3 instances)
gptModel = {
if (gptModelInstance) return gptModelInstance;
while (!gptModelInstance && modelLoadState.status !== 'error') {
await Promises.delay(200);
}
if (!gptModelInstance) {
throw new Error(modelLoadState.error ? modelLoadState.error.message : 'Model unavailable');
}
return gptModelInstance;
}// Custom logits processor to capture probabilities
LogitsCaptureProcessor = class extends transformers.LogitsProcessor {
constructor() {
super();
this.captured_logits = [];
}
_call(input_ids, logits) {
// Capture the logits for each generation step
// logits shape: [batch_size, vocab_size]
this.captured_logits.push(logits);
return logits; // Return unchanged
}
getSequentialPredictions(tokenizer) {
if (this.captured_logits.length === 0) return [];
const results = [];
// Process each captured logits tensor (one per generated token)
for (let step = 0; step < this.captured_logits.length; step++) {
const logitsTensor = this.captured_logits[step];
// Extract logits array
let logitsArray;
if (logitsTensor.dims.length === 2) {
const vocabSize = logitsTensor.dims[1];
logitsArray = Array.from(logitsTensor.data.slice(0, vocabSize));
} else {
logitsArray = Array.from(logitsTensor.data);
}
// Apply softmax
let maxLogit = -Infinity;
for (let j = 0; j < logitsArray.length; j++) {
const value = logitsArray[j];
if (value > maxLogit) {
maxLogit = value;
}
}
const expScores = logitsArray.map(x => Math.exp(x - maxLogit));
const sumExp = expScores.reduce((a, b) => a + b, 0);
const probs = expScores.map(x => x / sumExp);
// Get top-3 alternatives
const indexed = probs.map((p, i) => ({prob: p, index: i}));
indexed.sort((a, b) => b.prob - a.prob);
const top3 = indexed.slice(0, 3);
// Decode tokens
const mainToken = tokenizer.decode([top3[0].index], {skip_special_tokens: true});
const alternatives = top3.slice(1).map(item => {
const decoded = tokenizer.decode([item.index], {skip_special_tokens: true});
const displayToken = decoded.trim() || `[${item.index}]`;
return `${displayToken} (${(item.prob * 100).toFixed(1)}%)`;
}).join(', ');
results.push({
position: step + 1,
token: mainToken.trim() || `[${top3[0].index}]`,
probability: (top3[0].prob * 100).toFixed(1) + '%',
alternatives: alternatives
});
}
return results;
}
}// Generate next tokens with actual logit probabilities
gptPredictions = {
if (!gptText || gptText.length === 0) {
return [];
}
try {
// Tokenize input
const inputs = await gptTokenizer(gptText);
// Create logits processor
const logitsProcessor = new LogitsCaptureProcessor();
// Generate 6 tokens with logits processor
await gptModel.generate({
...inputs,
max_new_tokens: 6, // Generate 6 sequential tokens
// logits_processor: [logitsProcessor],
do_sample: false, // Greedy decoding to get the most likely sequence
top_k: 20,
temperature: 0.7,
max_new_tokens: 6,
logits_processor: [logitsProcessor]
});
// Extract predictions for each token position
const predictions = logitsProcessor.getSequentialPredictions(gptTokenizer);
return predictions;
} catch (error) {
console.error('GPT generation error:', error);
return [{position: 1, token: `Error: ${error.message}`, probability: '0.0%', alternatives: ''}];
}
}
// Display predictions in a styled table mounted in the div
gptTableDisplay = {
const predictions = await Promise.resolve(gptPredictions);
const targetDiv = document.getElementById('gpt-predictions-table');
if (!targetDiv) return html``;
if (!predictions || predictions.length === 0) {
targetDiv.innerHTML = '<div style="color: #d4d4d4;">Enter text to see predictions...</div>';
return html``;
}
const table = Inputs.table(predictions, {
columns: ["position", "token", "probability", "alternatives"],
header: {
position: "Pos",
token: "Token",
probability: "Probability",
alternatives: "Alternatives"
},
rows: predictions.length, // Show all rows without scrolling
height: null // Remove height constraint
});
// Apply dark styling
const tableEl = table.querySelector('table');
if (tableEl) {
tableEl.style.cssText = 'width: 100%; border-collapse: collapse; background-color: transparent; font-size: 0.85em;';
const thead = tableEl.querySelector('thead');
if (thead) {
thead.querySelectorAll('th').forEach(th => {
th.style.cssText = 'border: 1px solid #3e3e3e; font-weight: 600; background-color: #2d2d2d !important; color: #d4d4d4 !important; padding: 8px;';
});
}
tableEl.querySelectorAll('tbody td').forEach(td => {
td.style.cssText = 'border: 1px solid #3e3e3e; background-color: #1e1e1e; color: #d4d4d4; padding: 8px;';
});
}
// Remove any scrolling container
const scrollContainer = table.querySelector('.observablehq--inspect');
if (scrollContainer) {
scrollContainer.style.maxHeight = 'none';
scrollContainer.style.overflow = 'visible';
}
// Mount in target div
targetDiv.innerHTML = '';
targetDiv.appendChild(table);
return html``;
}Warning
The model is in its base form, without chat template.
BERT vs GPT


Summary of LLM types
| Type | Architecture | Training Objective | Attention | Use Cases |
|---|---|---|---|---|
| BERT | Encoder stack only | Masked Language Modeling (MLM) | Bidirectional | Classification, QA, NER, sentiment analysis |
| GPT | Decoder stack only | next token prediction | Unidirectional (left-to-right, autoregressive) | Text generation, chatbots, open-ended tasks |
| Seq2Seq | Encoder + Decoder stacks | Sequence-to-sequence | Encoder: Bidirectional; Decoder: Unidirectional | Translation, summarization, speech, data-to-text |
Summary of LLM types (2)
| Type | Strengths | Weaknesses | Example Models | Training Data | Inference Speed |
|---|---|---|---|---|---|
| BERT (Encoder-Only) | Deep understanding of input; discriminative tasks | Not designed for generation | BERT, RoBERTa, DistilBERT | Large corpus (masked tokens) | Fast (parallelizable) |
| GPT (Decoder-Only) | Coherent, fluent generation | No bidirectional context | GPT-3, GPT-4, Llama | Large corpus (autoregressive) | Slower (autoregressive) |
| Seq2Seq (Encoder-Decoder) | sequence transformation | requires aligned input-output pairs | T5, BART, Transformer (original), Whisper | Parallel corpora (input-output pairs) | Moderate (depends on sequence length) |
Generative LLMs, Base vs Instruct
- 🧠 Base models: just predict the next word (pre-training phase, no task-specific fine-tuning)
- 📝 Instruct models: fine-tuned on specific tasks and follow user instructions more effectively
Important
Never use the base model for specific tasks without fine-tuning.
Generative LLMs, Reasoning vs non-Reasoning
- 🤖 (Non-reasoning) models focus on generating coherent text without explicit reasoning capabilities
- Reasoning models:
- 🧩 complex reasoning tasks
- 🔗 multi-step problems
Tip
Reasoning addition to LLM have been a breakthrough in the field since end of 2024.
Reasoning Demo - Compare Outputs
// Input prompt for reasoning comparison
viewof reasoningPrompt = styleInput(Inputs.textarea({
label: "Enter a reasoning task (e.g., a math problem or logic puzzle)",
value: "Lily is three times older than her son. In 15 years, she will be twice as old as him. How old is she now?",
rows: 3,
width: 800
}))// Sequential generation: first reasoning, then direct
reasoningOutputs = {
const previousOutputs = storedReasoningOutputs;
const trigger = generateButton;
const currentTimestamp = trigger && trigger.timestamp;
// Check if button was clicked
if (!currentTimestamp || currentTimestamp === lastGenerationTimestamp) {
return previousOutputs;
}
const promptText = (trigger && trigger.text) ? `${trigger.text}`.trim() : "";
if (!promptText) {
mutable lastGenerationTimestamp = currentTimestamp;
return previousOutputs;
}
// Check if model and tokenizer are available
if (!reasoningModel || !reasoningTokenizer) {
const loadingOutputs = {
reasoning: {text: "Model is loading or failed to load. Please wait or refresh the page.", tokens: 0, time: 0},
direct: {text: "Model is loading or failed to load. Please wait or refresh the page.", tokens: 0, time: 0}
};
mutable storedReasoningOutputs = loadingOutputs;
mutable lastGenerationTimestamp = currentTimestamp;
return loadingOutputs;
}
try {
// FIRST: Generate with reasoning
mutable generationStatus = {reasoning: 'generating', direct: 'waiting'};
const startTime1 = performance.now();
const messages1 = [
{ role: "system", content: "You are a helpful assistant. Think step by step." },
{ role: "user", content: promptText }
];
const inputs1 = await reasoningTokenizer.apply_chat_template(messages1, {
add_generation_prompt: true,
return_dict: true,
enable_thinking: true
});
const outputs1 = await reasoningModel.generate({
...inputs1,
max_new_tokens: 2048,
do_sample: true,
temperature: 0.6,
top_p: 0.95,
top_k: 20,
});
const decoded1 = reasoningTokenizer.decode(outputs1[0], {skip_special_tokens: true});
const endTime1 = performance.now();
const parts1 = decoded1.split('assistant');
const response1 = parts1.length > 1 ? parts1[parts1.length - 1].trim() : decoded1;
const thinkingMatch = response1.match(/<think>([\s\S]*?)<\/think>/);
const reasoningAnswer = response1.replace(/<think>[\s\S]*?<\/think>/g, "").trim();
const reasoningResult = {
text: reasoningAnswer,
thinking: thinkingMatch ? thinkingMatch[1].trim() : undefined,
tokens: outputs1[0].length - (inputs1.input_ids.dims?.[1] ?? 0),
time: ((endTime1 - startTime1) / 1000).toFixed(2)
};
// SECOND: Generate direct answer (after reasoning completes)
mutable generationStatus = {reasoning: 'done', direct: 'generating'};
const startTime2 = performance.now();
const messages2 = [
{ role: "system", content: "You are a helpful assistant. Give a direct, concise answer." },
{ role: "user", content: promptText }
];
const inputs2 = await reasoningTokenizer.apply_chat_template(messages2, {
add_generation_prompt: true,
return_dict: true,
enable_thinking: false
});
const outputs2 = await reasoningModel.generate({
...inputs2,
do_sample: true,
temperature: 0.7,
top_p: 0.8,
top_k: 20,
max_new_tokens: 2048,
});
const decoded2 = reasoningTokenizer.decode(outputs2[0], {skip_special_tokens: true});
const endTime2 = performance.now();
const parts2 = decoded2.split('assistant');
const response2 = parts2.length > 1 ? parts2[parts2.length - 1].trim() : decoded2;
const directThinkingMatch = response2.match(/<think>([\s\S]*?)<\/think>/);
const directAnswer = response2.replace(/<think>[\s\S]*?<\/think>/g, "").trim();
const directResult = {
text: directAnswer,
thinking: directThinkingMatch ? directThinkingMatch[1].trim() : undefined,
tokens: outputs2[0].length - (inputs2.input_ids.dims?.[1] ?? 0),
time: ((endTime2 - startTime2) / 1000).toFixed(2)
};
const results = {
reasoning: reasoningResult,
direct: directResult
};
mutable storedReasoningOutputs = results;
mutable lastGenerationTimestamp = currentTimestamp;
mutable generationStatus = {reasoning: 'done', direct: 'done'};
return results;
} catch (error) {
console.error('Generation error:', error);
mutable generationStatus = {reasoning: 'error', direct: 'error'};
const errorOutputs = {
reasoning: {text: `Error: ${error.message}`, tokens: 0, time: 0},
direct: {text: `Error: ${error.message}`, tokens: 0, time: 0}
};
mutable storedReasoningOutputs = errorOutputs;
mutable lastGenerationTimestamp = currentTimestamp;
return errorOutputs;
}
}🧩 With Reasoning (step-by-step)
{
const { reasoning } = reasoningOutputs;
const thinkingSection = reasoning.thinking
? html`<div style="margin-bottom: 8px;"><div style="color: #ffa94d; font-size: 0.5em; margin-bottom: 4px;">🧠 Thinking</div><div style="background-color: #262626; color: #f0f0f0; border: 1px solid #3e3e3e; padding: 8px; border-radius: 4px; white-space: pre-wrap;">${reasoning.thinking}</div></div>`
: "";
return html`<div style="background-color: #1e1e1e; color: #d4d4d4; border: 1px solid #3e3e3e; padding: 12px; border-radius: 4px; height: 13.5em; overflow-y: auto; white-space: pre-wrap; font-family: monospace; font-size: 0.5em !important; line-height: 1.5;"><div style="display: flex; flex-direction: column; gap: 8px;">${thinkingSection}<div><div style="color: #79d2ff; font-size: 0.5em; margin-bottom: 4px;">💡 Answer</div><div>${reasoning.text || ""}</div></div></div></div>
<div style="color: #888; font-size: 0.5em; margin-top: 8px;">📊 ${reasoning.tokens} tokens • ⏱️ ${reasoning.time}s</div>`;
}🔍 Without Reasoning (direct answer)
html`<div style="background-color: #1e1e1e; color: #d4d4d4; border: 1px solid #3e3e3e; padding: 12px; border-radius: 4px; height: 13.5em; overflow-y: auto; white-space: pre-wrap; font-family: monospace; font-size: 0.5em !important; line-height: 1.5;">${reasoningOutputs.direct.text}</div>
<div style="color: #888; font-size: 0.5em !important; margin-top: 8px;">📊 ${reasoningOutputs.direct.tokens} tokens • ⏱️ ${reasoningOutputs.direct.time}s</div>`
The importance of the context window
- 🪟 The context window is crucial for understanding and generating text.
- 🧠 It determines how much information the model can consider at once.
- 📏 Larger context windows allow for better understanding of complex queries and generation of more coherent responses.
- 🔢 Typical max context windows are ~16k tokens; latest open-weight local LLMs reach 128k/256k/512k tokens; frontier LLMs are 1M+ tokens.
- 💸 Long context windows are computationally expensive and require more memory/GPU resources.
What happens when the context window is exceeded?
- 🪟 When the context window is exceeded, the model may lose track of important information, leading to less coherent responses.
- 🛠️ Strategies to handle this include:
- 📝 Summarizing previous context
- 💾 Using external memory stores
- 🧩 Chunking input data
Caution
Very large context (when permitted by the model) isn’t always a good thing: there are chances that the model may become overwhelmed with information, leading to decreased performance AND quality.
RAG (Retrieval-Augmented Generation)
- 🔗 RAG combines retrieval-based and generation-based approaches.
- 📚 It retrieves relevant documents from a knowledge base and uses them to inform the generation process.
- 🎯 This allows for more accurate and contextually relevant responses.

Turtlecrown, Wikipedia
{kind=link}
RAG Demo
// Precompute embeddings for documents using the shared transformers pipeline
documentEmbeddings = {
if (documents.length === 0) {
return [];
}
const pipeline = await similarityPipeline;
const texts = documents.map(doc => doc.text);
const output = await pipeline(texts, { pooling: 'mean', normalize: true });
const embeddingSize = output.dims?.[1] ?? (output.data.length / texts.length);
const vectors = texts.map((_, i) =>
Array.from(output.data.slice(i * embeddingSize, (i + 1) * embeddingSize))
);
return documents.map((doc, i) => ({
id: doc.id,
text: doc.text,
embedding: vectors[i]
}));
}// Function to compute cosine similarity
function cosineSimilarity(vecA, vecB) {
const dotProduct = vecA.reduce((sum, a, i) => sum + a * vecB[i], 0);
const magnitudeA = Math.sqrt(vecA.reduce((sum, a) => sum + a * a, 0));
const magnitudeB = Math.sqrt(vecB.reduce((sum, b) => sum + b * b, 0));
return dotProduct / (magnitudeA * magnitudeB);
}// Function to retrieve top-k relevant documents
async function retrieveDocuments(query, k = 2) {
if (documentEmbeddings.length === 0) {
return [];
}
const pipeline = await similarityPipeline;
const output = await pipeline(query, { pooling: 'mean', normalize: true });
const embeddingSize = output.dims?.[1] ?? output.data.length;
const queryEmbedding = Array.from(output.data.slice(0, embeddingSize));
const similarities = documentEmbeddings.map(doc => ({
id: doc.id,
text: doc.text,
similarity: cosineSimilarity(queryEmbedding, doc.embedding)
}));
similarities.sort((a, b) => b.similarity - a.similarity);
return similarities.slice(0, k);
}// Editable knowledge base facts (one per line)
viewof ragFactsInput = {
const input = styleInput(Inputs.textarea({
label: "Knowledge base facts (one per line)",
value: [
"[1929-1945] Okunoshima was used as a secret poison gas production site during WWII, under the supervision of the Imperial Japanese Army.",
"[1929-1945] The Okunoshima’s island facilities produced over 6,000 tons of chemical weapons, including mustard gas and tear gas, between 1929 and 1945.",
"[1946] After WWII, the Allied Occupation Forces ordered the destruction of all chemical weapons on Okunoshima, but many were dumped into the surrounding sea.",
"[1929-1945] The island of Okunoshima was erased from most maps during the war to maintain secrecy, earning it the nickname \"The Forgotten Island.\"",
"[1970s] In the 1970s, a small group of schoolchildren released 8 rabbits on Okunoshima as part of a field trip, unknowingly starting the island’s future rabbit population boom."
].join("\n"),
rows: 8,
width: 600
}));
input.querySelector('textarea').style.fontSize = '0.5em';
return input;
}
// Input query for RAG demo
viewof ragQuery = styleInput(Inputs.textarea({
label: "Enter a query",
value: "Why was Okunoshima hidden during WWII?",
rows: 1,
width: 600
}))
// Display retrieved documents
ragDisplay = {
const docs = retrievedDocs;
if (docs.length === 0) {
return html`<div style="color: #d4d4d4;">Enter a query to see retrieved documents...</div>`;
}
return html`<div style="background-color: #1e1e1e; color: #d4d4d4; border: 1px solid #3e3e3e; padding: 12px; border-radius: 4px; font-family: monospace; font-size: 0.5em !important; line-height: 1.5;">
<div style="font-weight: bold; margin-bottom: 8px;">Retrieved Documents:</div>
${docs.map(doc => html`<div style="margin-bottom: 8px; font-size: 0.7em"><div style="color: #79d2ff;">• ${doc.text}</div><div style="color: #888; font-size: 0.5em;">(Similarity: ${(doc.similarity * 100).toFixed(2)}%)</div></div>`)}
</div>`;
}// Generation using retrieved documents
ragGeneratedAnswer = {
// Check if model and tokenizer are available
if (!gptRAGModel || !gptRAGTokenizer) {
return "Model is loading or failed to load. Please wait or refresh the page.";
}
const query = ragQuery.trim();
const docs = retrievedDocs;
if (docs.length === 0) {
return "No documents retrieved.";
}
// Generate answer by calling the model with retrieved context in a templated prompt
const context = docs.map(doc => doc.text).join("\n");
const messages = [
{ role: "system", content: "You are a helpful assistant. Give an answer based on context." },
{ role: "user", content: `Based on the following documents, answer the question: ${query}\n\nContext:\n${context}\n` }
];
const inputs = await gptRAGTokenizer.apply_chat_template(messages, {
add_generation_prompt: true,
return_dict: true,
enable_thinking: false
});
const outputs = await gptRAGModel.generate({
...inputs,
do_sample: true,
temperature: 0.7,
top_p: 0.8,
top_k: 20,
max_new_tokens: 256,
});
const decoded = gptRAGTokenizer.decode(outputs[0], {skip_special_tokens: true});
const parts = decoded.split('assistant');
const response = parts.length > 1 ? parts[parts.length - 1].trim() : decoded;
// return html`<pre>${decoded}</pre>`;
return response;
}// Generation without retrieved context
ragNoContextAnswer = {
if (!gptRAGModel || !gptRAGTokenizer) {
return "Model is loading or failed to load. Please wait or refresh the page.";
}
const query = ragQuery.trim();
if (!query) {
return "Enter a query to generate an answer.";
}
const messages = [
{ role: "system", content: "You are a helpful assistant. Answer directly without external context." },
{ role: "user", content: query }
];
const inputs = await gptRAGTokenizer.apply_chat_template(messages, {
add_generation_prompt: true,
return_dict: true,
enable_thinking: false
});
const outputs = await gptRAGModel.generate({
...inputs,
do_sample: true,
temperature: 0.7,
top_p: 0.8,
top_k: 20,
max_new_tokens: 256,
});
const decoded = gptRAGTokenizer.decode(outputs[0], {skip_special_tokens: true});
const parts = decoded.split('assistant');
const response = parts.length > 1 ? parts[parts.length - 1].trim() : decoded;
return response;
}Generated answers will appear here.
ragAnswerDisplay = {
const targetDiv = document.getElementById('rag-answer-display');
if (!targetDiv) return html``;
const [contextAnswer, noContextAnswer] = await Promise.all([
Promise.resolve(ragGeneratedAnswer),
Promise.resolve(ragNoContextAnswer)
]);
if (!contextAnswer || !noContextAnswer) {
targetDiv.innerHTML = '<div style="color: #d4d4d4;">Generating answers...</div>';
return html``;
}
const outputs = html`<div style="display: flex; flex-wrap: wrap; gap: 16px;">
<div style="flex: 1 1 280px; background-color: #1e1e1e; color: #d4d4d4; border: 1px solid #3e3e3e; padding: 12px; border-radius: 4px; font-family: monospace; font-size: 0.5em !important; line-height: 1.5;">
<div style="font-weight: bold; margin-bottom: 8px;">With retrieved context</div>
<div>${contextAnswer}</div>
</div>
<div style="flex: 1 1 280px; background-color: #1e1e1e; color: #d4d4d4; border: 1px solid #3e3e3e; padding: 12px; border-radius: 4px; font-family: monospace; font-size: 0.5em !important; line-height: 1.5;">
<div style="font-weight: bold; margin-bottom: 8px;">Without context</div>
<div>${noContextAnswer}</div>
</div>
</div>`;
targetDiv.innerHTML = '';
targetDiv.appendChild(outputs);
return html``;
}Concerns
Hallucinations
Was King Renoit real?Is King Renoit mentioned in the Song of Roland, yes or no?Hallucinations are STRUCTURAL to LLMs
- There is no way to eliminate hallucinations in LLMs (only mitigate them)
- Hallucinations are a byproduct of the probabilistic nature of LLMs
- Hallucinations are more likely when:
- The model is uncertain about the next token
- The input prompt is ambiguous or lacks context
- The model is asked to generate information outside its training data
Training data sets
- very large dataset: (570Gb of text data, 499 B of tokens) for BERT (2018)
{
var data = [{
values: [3, 8, 7, 22, 60],
labels: ["Wikipedia", "Books1", "Books2", "Webtext2", "Common Crawl"],
textinfo: "label+percent",
type: "pie",
marker: {
colors: ["lightcyan", "cyan", "royalblue", "darkblue", "gold"]
}
}];
var layout = {
template: 'plotly_dark',
paper_bgcolor: "rgba(0,0,0,0)",
plot_bgcolor: "rgba(0,0,0,0)",
font: {
size: 14,
color: "white"
},
height: 450,
width: 450,
margin: {"t": 0, "b": 0, "l": 0, "r": 0},
showlegend: false
};
const div = document.createElement('div');
Plotly.newPlot(div, data, layout,{displayModeBar: false});
return div;
}Repartition of the training dataset
Underrepresentation on the web means less accuracy and more hallucinations!
- Other data (chosen quality)
- Weighted sampling: Wikipedia=5 x CommonCrawl, Books1=20 x CommonCrawl,…
Copyright issues, be careful no way to check truthfulness
Aside: ELIZA, The First Chatbot (1966)
// ELIZA implementation
elizaPatterns = [
{
pattern: /\bI need (.*)/i,
responses: ["Why do you need {0}?", "Would it really help you to get {0}?", "Are you sure you need {0}?"]
},
{
pattern: /\bI am (.*)/i,
responses: ["How long have you been {0}?", "Do you believe it is normal to be {0}?", "Do you enjoy being {0}?"]
},
{
pattern: /\bI feel (.*)/i,
responses: ["Tell me more about feeling {0}.", "Do you often feel {0}?", "What makes you feel {0}?"]
},
{
pattern: /\bI (.*) you/i,
responses: ["Why do you {0} me?", "Does it please you to {0} me?", "What makes you {0} me?"]
},
{
pattern: /\bmy (.*)/i,
responses: ["Tell me more about your {0}.", "Why is your {0} important to you?", "Your {0}?"]
},
{
pattern: /\b(mother|father|mom|dad)\b/i,
responses: ["Tell me more about your family.", "How do you feel about your family?", "Your family seems important to you."]
},
{
pattern: /\b(sad|unhappy|depressed)\b/i,
responses: ["I'm sorry to hear you are feeling that way.", "Can you explain what is making you feel this way?"]
},
{
pattern: /\b(happy|excited|glad)\b/i,
responses: ["That's wonderful! What makes you feel this way?", "I'm glad to hear that!"]
},
{
pattern: /\byes\b/i,
responses: ["I see.", "And how does that make you feel?", "Can you elaborate on that?"]
},
{
pattern: /\bno\b/i,
responses: ["Why not?", "Are you sure?", "Can you explain?"]
},
{
pattern: /.*/,
responses: [
"Please tell me more.",
"I see. Go on.",
"How does that make you feel?",
"What does that suggest to you?",
"Can you elaborate on that?"
]
}
]
// ELIZA response generator
function elizaRespond(input) {
if (!input || input.trim() === "") {
return "Please say something.";
}
for (let i = 0; i < elizaPatterns.length; i++) {
const { pattern, responses } = elizaPatterns[i];
const match = input.match(pattern);
if (match) {
// Pick a random response
const response = responses[Math.floor(Math.random() * responses.length)];
// Replace {0} with captured group if exists
if (match[1]) {
return response.replace("{0}", match[1]);
}
return response;
}
}
return "I'm not sure I understand. Can you rephrase that?";
}
// Chat history state with two starter turns
mutable elizaChatHistory = [
{ role: "user", text: "Hi Eliza, I feel like the workload never ends" },
{ role: "eliza", text: elizaRespond("Do you often feel like the workload never ends?") },
{ role: "user", text: "I feel depressed about it." },
{ role: "eliza", text: elizaRespond("Tell me more about feeling depressed about it.") }
]
// Input value state
mutable elizaInputValue = ""
// Send action state
mutable elizaSendAction = null
// Persistent textarea element
mutable elizaTextarea = null
// Input field
viewof elizaInput = {
if (!elizaTextarea) {
const container = document.createElement('div');
container.innerHTML = `<label style="display: block; margin-bottom: 4px; color: #d4d4d4;">Talk to ELIZA</label><textarea placeholder="Type your message here..." rows="2" style="background-color: #1e1e1e; color: #d4d4d4; border: 1px solid #3e3e3e; padding: 8px; border-radius: 4px; width: 90%;"></textarea>`;
const textarea = container.querySelector('textarea');
textarea.oninput = () => mutable elizaInputValue = textarea.value;
textarea.onkeydown = (e) => {
if (e.key === 'Enter' && !e.shiftKey) {
e.preventDefault();
if (textarea.value.trim()) {
mutable elizaSendAction = {timestamp: Date.now(), text: textarea.value};
}
}
};
mutable elizaTextarea = textarea;
return container;
} else {
// Update value only if different to avoid unnecessary updates
if (elizaTextarea.value !== elizaInputValue) {
elizaTextarea.value = elizaInputValue;
}
return elizaTextarea.parentElement;
}
}
// Process input and update chat
elizaChatUpdate = {
if (elizaSendAction && elizaSendAction.text && elizaSendAction.text.trim() !== "") {
const userMsg = elizaSendAction.text.trim();
const botResponse = elizaRespond(userMsg);
// Add user message and bot response to history
const newHistory = [
...elizaChatHistory,
{ role: "user", text: userMsg },
{ role: "eliza", text: botResponse }
];
Object.assign(elizaChatHistory, newHistory);
// Clear input
mutable elizaInputValue = "";
mutable elizaSendAction = null;
}
return html``;
}
// Display chat history
elizaChatDisplay = {
// Trigger on update
elizaChatUpdate;
if (elizaChatHistory.length === 0) {
return html`<div style="background-color: #1e1e1e; color: #888; border: 1px solid #3e3e3e; padding: 16px; border-radius: 4px; height: 300px; overflow-y: auto; display: flex; align-items: center; justify-content: center;">
Start a conversation with ELIZA...
</div>`;
}
const messages = elizaChatHistory.map(msg => {
const isUser = msg.role === "user";
const bgColor = isUser ? "#2d2d2d" : "#1e3a1e";
const align = isUser ? "right" : "left";
const label = isUser ? "You" : "ELIZA";
return `<div style="text-align: ${align}; margin-bottom: 12px;">
<div style="display: inline-block; max-width: 70%; text-align: left;">
<div style="font-size: 0.75em; color: #888; margin-bottom: 4px;">${label}</div>
<div style="background-color: ${bgColor}; color: #d4d4d4; padding: 10px; border-radius: 8px; font-size: 0.6em; border: 1px solid #3e3e3e;">
${msg.text}
</div>
</div>
</div>`;
}).join('');
// Create a stable container element so we can attach observers and reliably scroll
const container = document.createElement('div');
container.style.cssText = 'background-color: #1e1e1e; border: 1px solid #3e3e3e; padding: 16px; border-radius: 4px; height: 300px; overflow-y: auto;';
// Inner messages wrapper
const messagesWrapper = document.createElement('div');
messagesWrapper.innerHTML = messages;
container.appendChild(messagesWrapper);
// If chat is long, ensure we scroll to bottom after the content is mounted.
// Use MutationObserver to detect DOM changes, then requestAnimationFrame to let browser layout complete.
const doScroll = () => {
requestAnimationFrame(() => {
container.scrollTop = container.scrollHeight;
});
};
// If there are new messages, scroll once now.
doScroll();
// Set up a short-lived observer that scrolls when childList or subtree changes.
// We attach it each time the cell runs and disconnect after the first change to avoid leaks.
const observer = new MutationObserver((mutationsList) => {
// If any mutation added nodes, scroll to bottom on next frame
if (mutationsList.some(m => m.addedNodes && m.addedNodes.length > 0)) {
doScroll();
}
});
observer.observe(messagesWrapper, { childList: true, subtree: true });
// Disconnect after 500ms to avoid keeping it running forever (reasonable for interactive updates)
setTimeout(() => {
try { observer.disconnect(); } catch (e) { /* ignore */ }
}, 500);
return container;
}Note
- ELIZA: Used templates and pattern-matching for simple dialogue.
- Modern LLMs: Use deep learning and huge datasets for coherent responses.
The Eliza effect
- 🧩 ELIZA (1966): simple rule‑based program, illusion of conversation.
- 🧠 Anthropomorphization: people project human traits, intentions, emotions onto machine outputs.
- 🤖 Modern LLMs: far more fluent, context‑aware; amplification of perception of human agency.
- ⚠️ Risks: overtrust if seen as intentional.
What is AI Slop?
- Definition: 🗑️ Low-quality, high-volume AI-generated content.
- Characteristics:
- 📦 Prioritizes speed and quantity over accuracy and relevance.
- 🧹 Often described as “digital clutter” or “filler content.”
- Examples:
- 💬 Vague, buzzword-filled text.
- ⚡ Hastily made memes or misleading news articles.
- ❌ Content that lacks coherence or original insight.
Blatant AI slop examples
| According to Smith et al. (2023), the flux constant is 12.7 | fabricated citation with a bogus numeric constant. |
|---|---|
| Convert 5 pounds to kilograms: 5 lb = 9.8 kg | wrong unit conversion that doubles the correct value. |
| Dr. Helena Vorov is leading the Mars hydrology program | a fully hallucinated expert and program. |
| The sky tastes triangular today; algorithmic candor suggests we pivot to purple clocks, and thus synergy blooms. | Senseless blather with rhythmic but meaningless phrasing. |
Impact and Challenges of AI Slop
- Impact on Information Ecosystems 🌐:
- 🔒 Undermines trust in online content and academic research.
- 🧭 Makes it harder to find reliable, high-quality information.
- Structural Issues 📱:
- 💸 Driven by platform monetization and ease of content generation.
- ♻️ Not a passing trend, but a persistent feature of modern media.
- Assessment and Risks ⚠️:
- 📏 Subjective but measurable through dimensions like coherence and relevance.
- ❗ Can spread misinformation and “careless speech” at scale.
- 🎮 Algorithmic virality: Low-cost, fast production “games the system.”
The peculiar writing style of LLMs
- 🤖 AI outputs show recurring rhetoric patterns (diptyques, triptyques).
- 🎭 These patterns reduce language diversity.
- 🔁 Feedback loop: generated text trains future models, amplifying sameness.
\Rightarrow🕵️ Build detection tools
Reflections on LLM narratives
- 👻 Scary stories of “too smart” LLMs: prompt tricks for marketing or corporate “puffery”.
- 🤔 Deliberately confuse design choices with emergent properties.
- 🚫 They don’t communicate risks clearly; no testable failures explained.
Human considerations
![]()
Human cost to AI development:
\RightarrowLabor conditions in content moderation
Labor conditions in AI content moderation
- 🤖 OpenAI outsources content moderation to Sama (San Francisco company)
- 🌍 Sama employs Kenyan workers (underpaid, exposed to toxic content, alienating work)
- 🚫 Denied sessions with wellness counselors
- ⚖️ Lawsuits in progress with Meta in Nairobi
Source Time Magazine, 2023
“Outsourcing trauma to the developing world”
- 🏙️ Workers are approached in Kibera, the largest informal settlement in Africa
- 💸 Salaries are too low to improve their situation, only keep it
- ✊ Attempts to unionize in 2024: mass-firing in retaliation in favor of Majorel (🇫🇷 French company)
![]()
Source Time Magazine, 2023
Ecological impact of AI 🌍
Key takeaways (Shift Project, Oct 2025)
- 🌐 Digital growth 🚀 outpaces decarbonization goals.
- 🤖 Generative AI boosts server & data center demand.
- ⚡ Digital sector uses lots of electricity & emits CO₂.
- 🌍 +9% greenhouse gas emissions per year, even with decarbonized electricity mix
- 🎯 -5% per year needed to reach net zero emissions target
- 🚫 By 2030, the projected trajectory for data centers is unsustainable.
- ⚠️ Up to 920 MtCO₂e/year—up to 2× France’s annual emissions.
The Shift Project 2025 Source reformated by us
Electricity consumption
The Shift Project 2025 Source reformated by us
Exploratory prospective scenario of undifferentiated deployment of compute supply and its widespread adoption
{
const data = await d3.dsv(";","materials/shift-data.csv", d3.autoType);
const years = data.columns.slice(1);
// First column of each row is the category
// Other columns are years
// Build traces: first 3 rows as stacked bars, others as line traces
const traces = data.map((row, i) => {
const base = {
name: row[data.columns[0]],
x: years,
y: years.map(y => row[y])
};
if (i < 3) {
// stacked bar
return Object.assign(base, { type: 'bar', marker: { opacity: 0.95 } });
} else {
// line trace
return Object.assign(base, { type: 'scatter', mode: 'lines+markers', line: { shape: 'spline' } });
}
});
const layout = {
template: 'plotly_dark',
paper_bgcolor: "rgba(0,0,0,0)",
plot_bgcolor: "rgba(0,0,0,0)",
font: {
size: 14,
color: "white"
},
height: 460,
width: 800,
margin: {"t": 30, "b": 30, "l": 80, "r": 30},
barmode: 'stack',
legend: { traceorder: 'normal' },
yaxis: {
title: {
text: 'Electricity consumption of data centers (TWh)',
font: {
family: 'Courier New, monospace',
size: 16,
color: '#7f7f7f'
},
standoff: 20
// offset to 10px left
},
automargin: true
},
xaxis: {
title: {
text: 'Year',
font: {
family: 'Courier New, monospace',
size: 16,
color: '#7f7f7f'
},
standoff: 20
},
automargin: true
},
};
const div = document.querySelector('#shift-plot');
Plotly.newPlot(div, traces, layout,{displayModeBar: false});
return html``;
}AI Usage projection
{
const csv = `Year,Total AI,Gen AI Training,Gen AI Inferencing,Trad AI Training,Trad AI Inferencing,Min - Total AI,Max - Total AI
2025,100,47,40,9,4,90,180
2026,214,95,96,18,5,180,328
2027,406,166,162,66,12,328,496
2028,632,266,254,198,14,496,611
2029,793,327,323,127,16,611,766
2030,880,407,416,51,6,766,1070
`
const data = await d3.csvParse(csv, d3.autoType);
// first line is header
// each row is a year
// plot by columns
console.log(data);
const years = data.map(d => d.Year);
const traces = data.columns.slice(1).map(col => {
return {
name: col,
x: years,
y: data.map(d => d[col]),
type: col.includes("Min") || col.includes("Max") ? 'scatter' : 'bar',
mode: col.includes("Min") || col.includes("Max") ? 'lines+markers' : undefined,
line: col.includes("Min") || col.includes("Max") ? { shape: 'spline' } : undefined,
marker: { opacity: 0.95 }
};
});
const layout = {
template: 'plotly_dark',
paper_bgcolor: "rgba(0,0,0,0)",
plot_bgcolor: "rgba(0,0,0,0)",
font: {
size: 14,
color: "white"
},
height: 460,
width: 800,
margin: {"t": 30, "b": 30, "l": 80, "r": 30},
legend: { traceorder: 'normal' },
yaxis: {
title: {
text: 'Electricity consumption of AI (TWh)',
font: {
family: 'Courier New, monospace',
size: 16,
color: '#7f7f7f'
},
standoff: 20
// offset to 10px left
},
automargin: true
},
xaxis: {
title: {
text: 'Year',
font: {
family: 'Courier New, monospace',
size: 16,
color: '#7f7f7f'
},
standoff: 20
},
automargin: true
},
};
const div = document.createElement('div');
Plotly.newPlot(div, traces, layout,{displayModeBar: false});
console.log(div);
return div;
}Aboundance without boundaries scenario, by usage.
Source Scheider Electric reformated by us
Drivers and risks
- 🔄 Generative AI creates a cycle: more compute → more use.
- ⚠️ Risks: fossil lock-in 🛢️, water use 💧, server footprint 🖥️, regional carbon gaps 🌎.
- 🚫 Without rules, growth stays unsustainable.
The Shift Project 2025 Source reformated by us
Practical recommendations 🛠️
- 📊 Track & report energy, carbon, water for AI.
- 🏦 Set energy-carbon budgets for organizations.
- 🤔 Ask: do we need big models? Use leaner options when possible.
- 🌱 Eco-design: sample smart, use green grids, right-size models, drop unsustainable services.
The Shift Project 2025 Source reformated by us
Another perspective on AI energy use
- 🤖 Sometimes, AI can emit less CO₂ than humans for some tasks.
- 📊 Results depend on boundaries, hardware, reuse, and downstream effects.
- 🧩 Treat single studies as one data point; compare methods and scopes.
- 🗣️ Use as debate counterpoint; stress need for standard metrics before policy decisions.
Source Nature, 2024
Small, “on-demand” language models advocacy
Key points
- 🤏 Not all LLMs are huge; smaller models can be effective and efficient.
- 💸 Smaller models reduce costs, latency, and environmental impact.
- 🔓 On-device models enhance privacy and accessibility.
- 🎯 Choose model size based on task needs; bigger isn’t always better.
Small models for specific tasks
- 🤏 Small models excel in specific tasks (e.g., text classification, sentiment analysis).
- ⚡ They can be fine-tuned quickly with less data and compute.
- 💡 Often match or exceed large model performance on niche tasks.
- 🔄 Enable rapid experimentation and iteration.
\Rightarrow 🚀 Small models foster innovation by lowering entry barriers for developers and researchers.
AI Agents
AI agents are a programming paradigm involving two main flavours:
- Reactive agents 🤖: respond to inputs with pre-defined or LLM-driven actions (the agent “reacts” and may decide next steps).
- Pipelined agents 🔁: process inputs through a series of stages/components (the program orchestrates calls and post-processing).
Control flow distinction ⚙️:
- internal control = reactive (the LLM drives decisions)
- external control = pipeline (the programmer decides when/how to call the LLM)
Reactive agents
Examples:
- 🤖 Chatbots that respond to user queries with pre-defined answers.
- ⚙️ Simple automation scripts that trigger actions based on specific events (e.g., web search).
- 🧭 Agentic mode in Code Assistants — autonomous actions and decision-making.
Warning
\Rightarrow Control is done by the LLM itself with all risks : infinite loops, unsupervised and potentially dangerous actions etc.

Pipeline Agents
Examples:
- 🔍 RAG queries
- 📝 Summarizing documents
- 🔗 Communicating with other agents
Note
\Rightarrow Control is done by normal, program logic

Reactive agent 2025 : MCP
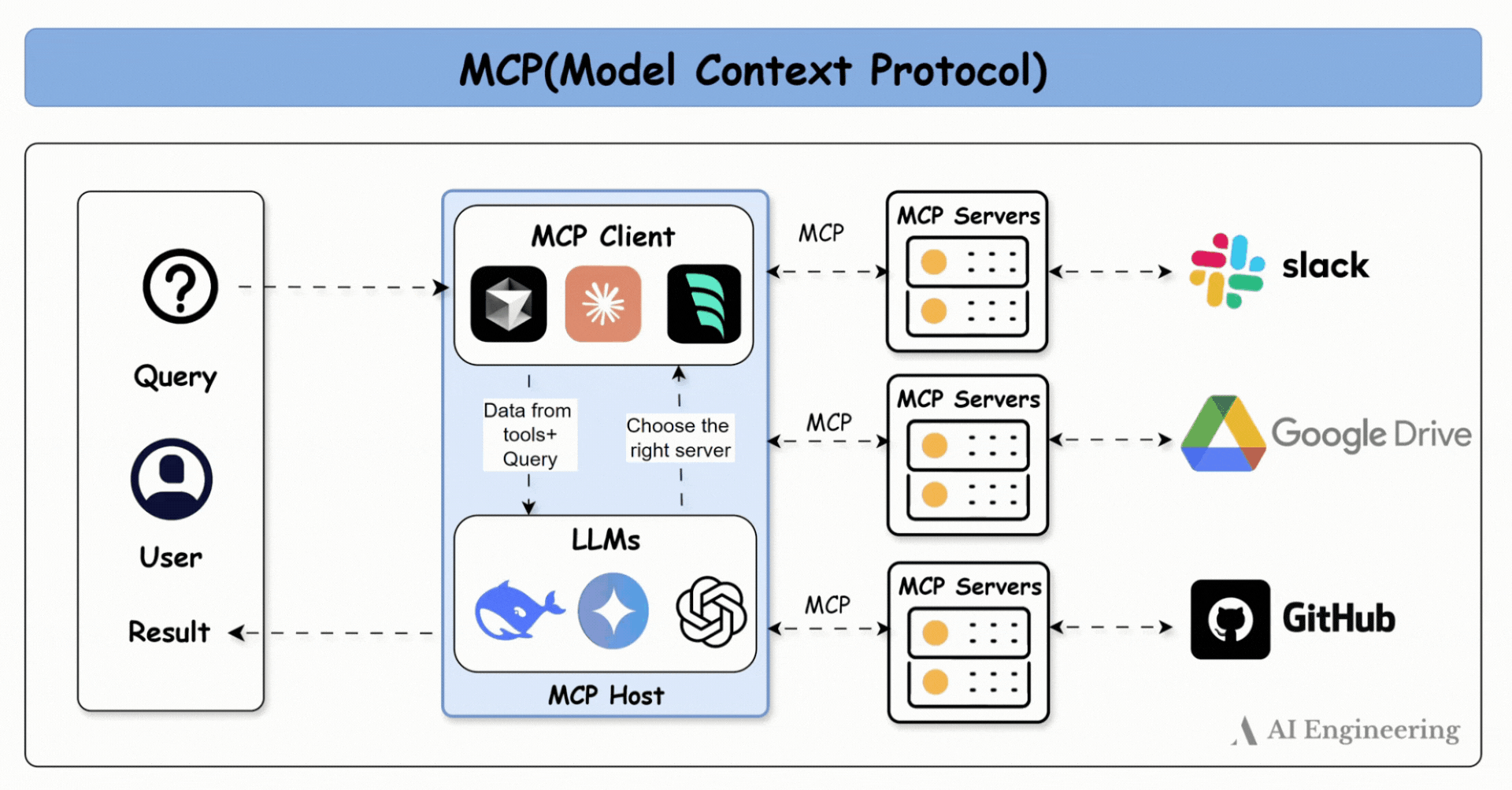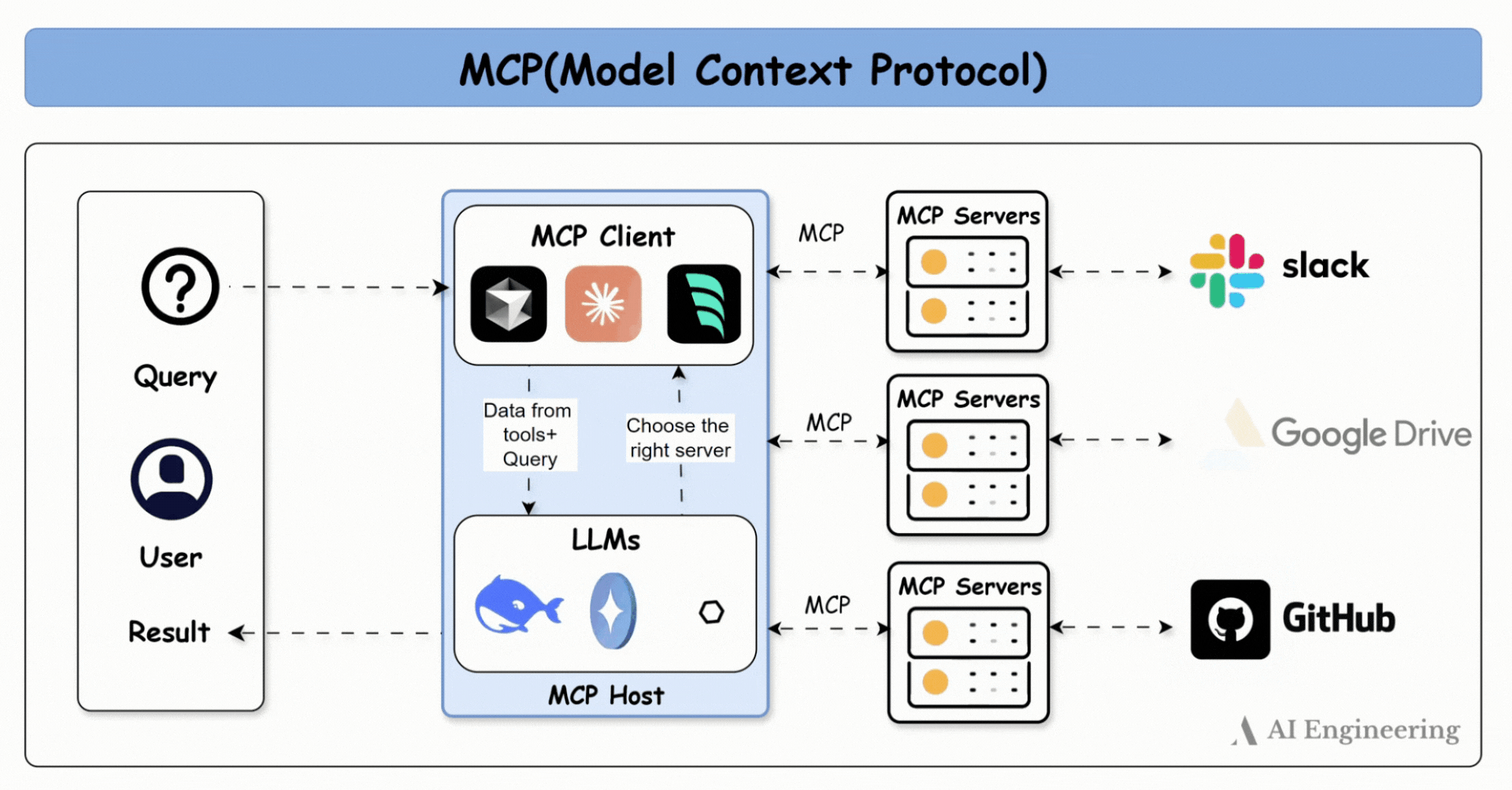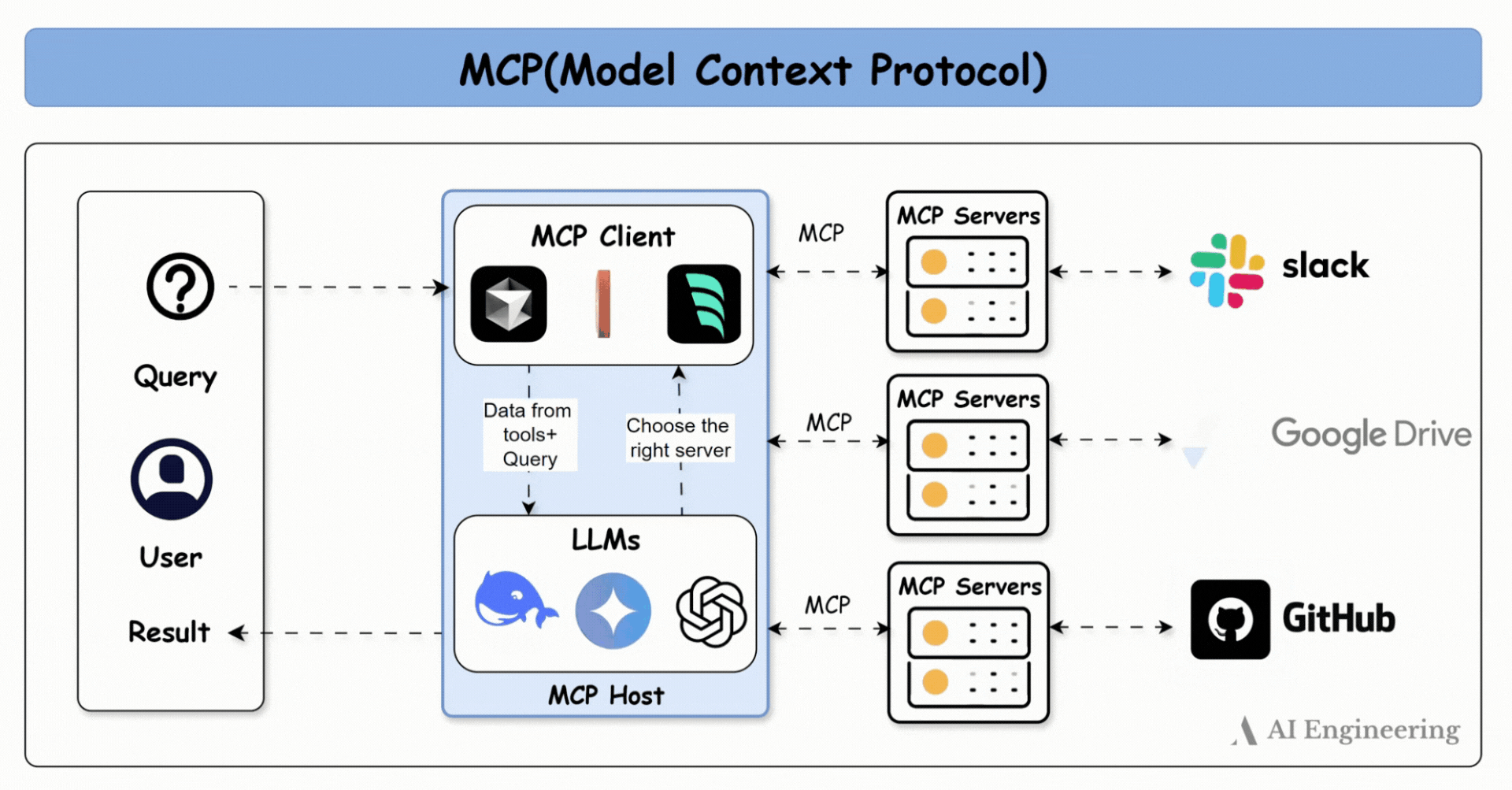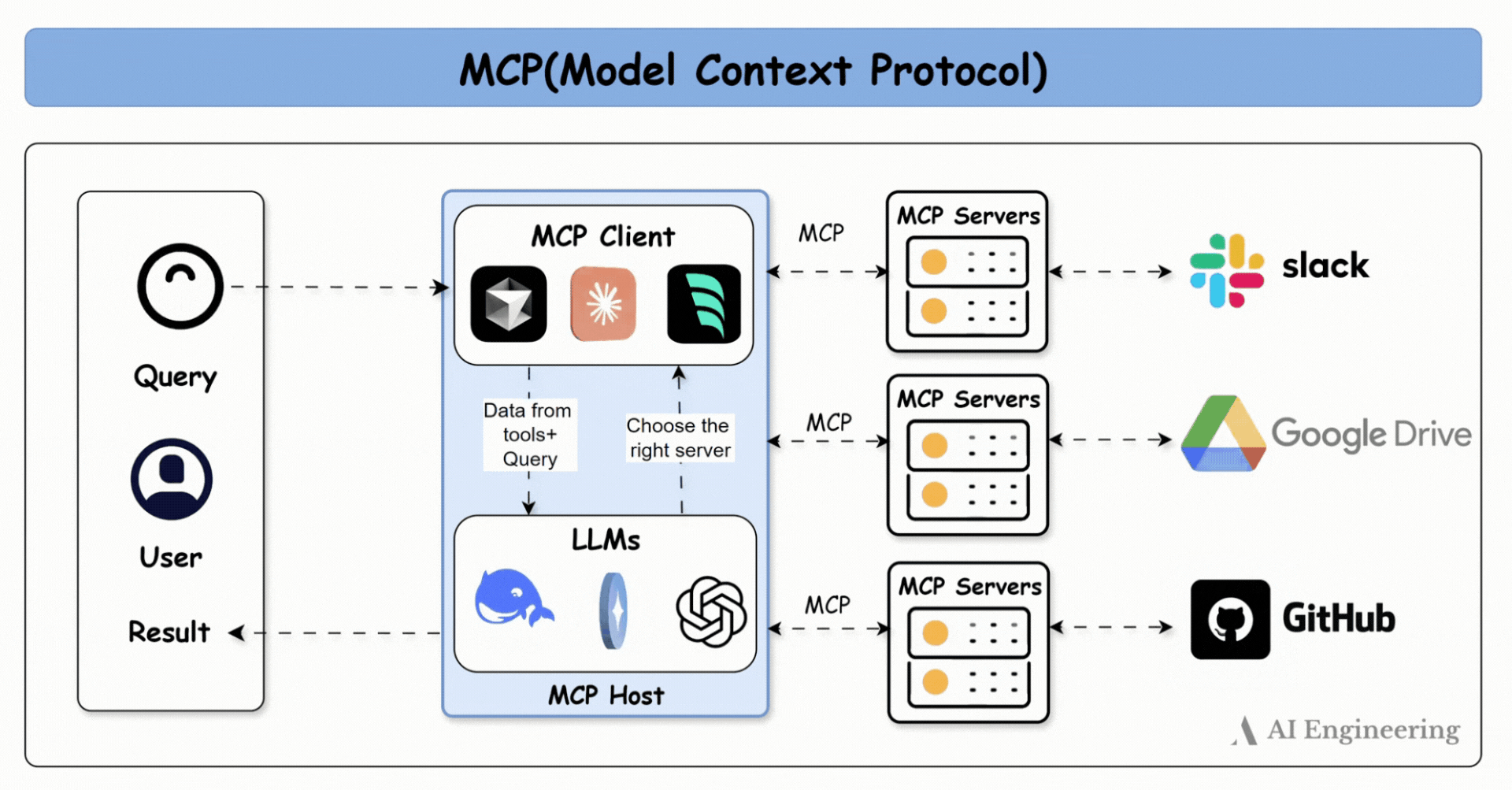
Ujjwal Khadka Source
Agent demo, Wikipedia search
- In the next slide we’ll build a simple reactive agent that:
- 📝 Takes a user query
- 🤖 Generates 2-3 search queries using GPT-decoder
- 🔍 Searches Wikipedia for each query
- 📄 Fetches the content of the top article for each query
- ✂️ Chunks the content into smaller pieces
- 🧬 Embeds the chunks and stores them in a vector database
- 🎯 Retrieves the top 3 relevant chunks for the original user query
- 💡 Generates an answer using the retrieved chunks as context
Agent demo
viewof queryInput = styleInput(Inputs.text({
label: "Enter your query:",
value: "What is the difference between machine learning and deep learning?",
width: 600
}))
viewof runButton = {
const button = Inputs.button("Run Agent", { value: 0, reduce: value => (value ?? 0) + 1 });
button.style.color = "#103c92";
button.style.fontSize = "0.9em";
return button;
}
generateSearchQueries = async query => {
if (!gptRAGModel || !gptRAGTokenizer) {
console.warn('LLM not ready, falling back to simple query');
return [query.trim()];
}
const prompt = `Extract 2-3 key topics from this question. Just the main nouns, nothing else.
Question: ${query}
Topics:`;
try {
const messages = [
{ role: 'user', content: prompt }
];
const inputs = await gptRAGTokenizer.apply_chat_template(messages, {
add_generation_prompt: true,
return_dict: true,
enable_thinking: false
});
const outputs = await gptRAGModel.generate({
...inputs,
do_sample: false,
temperature: 0.0,
max_new_tokens: 50
});
const decoded = gptRAGTokenizer.decode(outputs[0], { skip_special_tokens: true });
const parts = decoded.split('assistant');
let response = parts.length > 1 ? parts[parts.length - 1].trim() : decoded.trim();
// Remove any <think> tags
response = response.replace(/<think>[\s\S]*?<\/think>/g, '').trim();
// Parse comma-separated queries and clean markdown
const queries = response
.split(/[,\n]+/)
.map(q => q.trim())
.map(q => q.replace(/\*\*|\*\*$/g, '')) // Remove ** markdown
.map(q => q.replace(/^-\s*/, '')) // Remove leading - bullet
.map(q => q.replace(/^\d+\.\s*/, '')) // Remove numbered lists
.map(q => q.trim())
.filter(q => q.length > 0 && q.length < 50)
.slice(0, 3);
return queries.length > 0 ? queries : [query.trim()];
} catch (error) {
console.error('Search query generation failed:', error);
return [query.trim()];
}
}
getWikipediaPage = async title => {
try {
// Try direct page access first (handles redirects automatically)
const apiUrl = `https://en.wikipedia.org/w/api.php?action=query&prop=extracts&explaintext=1&titles=${encodeURIComponent(title)}&format=json&origin=*&redirects=1`;
const response = await fetch(apiUrl);
const data = await response.json();
const pages = data.query.pages;
const pageId = Object.keys(pages)[0];
if (pageId !== '-1' && pages[pageId].extract) {
const actualTitle = pages[pageId].title;
const url = `https://en.wikipedia.org/wiki/${encodeURIComponent(actualTitle.replace(/ /g, '_'))}`;
return { url, content: pages[pageId].extract };
}
return null;
} catch (e) {
console.error(`Direct page access error for '${title}':`, e);
return null;
}
}
searchWikipedia = async query => {
try {
const searchUrl = `https://en.wikipedia.org/w/api.php?action=opensearch&search=${encodeURIComponent(query)}&limit=1&format=json&origin=*`;
const response = await fetch(searchUrl);
const data = await response.json();
if (data.length > 3 && data[3].length > 0) {
return data[3][0];
}
} catch (e) {
console.error(`Search error for '${query}':`, e);
}
return null;
}
fetchContent = async url => {
try {
const pageTitle = url.split("/").pop();
const apiUrl = `https://en.wikipedia.org/w/api.php?action=query&prop=extracts&explaintext=1&titles=${pageTitle}&format=json&origin=*`;
const response = await fetch(apiUrl);
const data = await response.json();
const pages = data.query.pages;
for (const pageId in pages) {
const extract = pages[pageId].extract || "";
return extract;
}
} catch (e) {
console.error(`Fetch error for '${url}':`, e);
}
return "";
}
MAX_CHUNK_WORDS = 140;
MIN_CHUNK_WORDS = 60;
CHUNK_OVERLAP_SENTENCES = 1;
chunkDocument = (content, title, url) => {
const sentences = content
.split(/(?<=\.)\s+/)
.map(sentence => sentence.trim())
.filter(Boolean);
const chunks = [];
let buffer = [];
let wordCount = 0;
let chunkIndex = 0;
const flushBuffer = () => {
if (!buffer.length) return;
const chunkText = buffer.join(' ').trim();
const words = chunkText.split(/\s+/).filter(Boolean);
if (words.length >= MIN_CHUNK_WORDS) {
chunks.push({
title: title.replace(/_/g, ' '),
url,
text: chunkText,
index: chunkIndex
});
chunkIndex += 1;
}
};
sentences.forEach(sentence => {
const words = sentence.split(/\s+/).filter(Boolean);
if (wordCount + words.length > MAX_CHUNK_WORDS && buffer.length) {
flushBuffer();
buffer = buffer.slice(-CHUNK_OVERLAP_SENTENCES);
wordCount = buffer.join(' ').split(/\s+/).filter(Boolean).length;
}
buffer.push(sentence);
wordCount += words.length;
});
flushBuffer();
return chunks;
}
retrieveChunks = async (query, embeddedChunks, k = 3) => {
if (!embeddedChunks.length) return [];
const pipeline = await similarityPipeline;
const output = await pipeline(query, { pooling: 'mean', normalize: true });
const embeddingSize = output.dims?.[1] ?? output.data.length;
const queryEmbedding = Array.from(output.data.slice(0, embeddingSize));
const scored = embeddedChunks.map(chunk => ({
chunk,
similarity: cosineSimilarity(queryEmbedding, chunk.embedding)
})).sort((a, b) => b.similarity - a.similarity);
return scored.slice(0, Math.min(k, scored.length));
}
extractSnippet = text => {
const sentences = text.split(/(?<=\.)\s+/).map(s => s.trim()).filter(Boolean);
if (!sentences.length) return text.trim();
const candidate = sentences.find(sentence => sentence.length >= 60);
return candidate || sentences[0];
}
generateAnswer = async (query, retrieved) => {
if (!gptRAGModel || !gptRAGTokenizer) {
return {
answer: 'Language model not ready. Please wait and try again.',
error: true
};
}
if (!retrieved.length) {
return {
answer: 'No relevant context retrieved to answer the question.',
error: false
};
}
const contextBlocks = retrieved.map(({ chunk }, idx) => `### Source ${idx + 1}: ${chunk.title}
${chunk.text}`).join('\n\n');
const messages = [
{ role: 'system', content: 'You answer questions using only the provided context. Cite the source title when you use specific facts.' },
{ role: 'user', content: `Question: ${query}\n\nContext:\n${contextBlocks}\n\nAnswer:` }
];
const inputs = await gptRAGTokenizer.apply_chat_template(messages, {
add_generation_prompt: true,
return_dict: true,
enable_thinking: false
});
const outputs = await gptRAGModel.generate({
...inputs,
do_sample: false,
temperature: 0.0,
max_new_tokens: 320
});
const decoded = gptRAGTokenizer.decode(outputs[0], { skip_special_tokens: true });
const parts = decoded.split('assistant');
let response = parts.length > 1 ? parts[parts.length - 1].trim() : decoded.trim();
// Remove <think>...</think> tags if present
response = response.replace(/<think>[\s\S]*?<\/think>/g, '').trim();
return { answer: response, error: false };
}mutable agentState = ({
status: 'idle',
query: '',
logs: [],
searchQueries: [],
urls: [],
contexts: [],
embeddingProgress: [],
retrievedChunks: [],
answer: '',
error: null
});
mutable lastRunButton = 0
runAgent = async query => {
console.log('[runAgent] Starting with query:', query);
const state = {
status: 'running',
query,
logs: [],
searchQueries: [],
urls: [],
contexts: [],
embeddingProgress: [],
retrievedChunks: [],
answer: '',
error: null
};
const update = () => {
console.log('[runAgent] Updating state:', state.status, state.logs.length);
mutable agentState = {
...state,
logs: [...state.logs],
searchQueries: [...state.searchQueries],
urls: state.urls.map(item => ({ ...item })),
contexts: state.contexts.map(item => ({ ...item })),
embeddingProgress: state.embeddingProgress.map(item => ({ ...item })),
retrievedChunks: state.retrievedChunks.map(item => ({ ...item }))
};
};
const log = message => {
console.log('[runAgent]', message);
state.logs = [...state.logs, message];
update();
};
const contextsFull = [];
const finish = status => {
state.status = status;
update();
};
try {
update();
log('🤔 Query received');
} catch (initError) {
console.error('[runAgent] Init error:', initError);
state.error = 'Initialization failed: ' + initError.message;
state.status = 'error';
update();
return state;
}
try {
log('🔍 Generating search queries...');
const searchQueries = await generateSearchQueries(query);
state.searchQueries = searchQueries;
update();
if (!searchQueries.length) {
log('⚠️ Unable to derive searchable terms from the query.');
finish('done');
return state;
}
log(`🔍 Generated searches: ${searchQueries.join(', ')}`);
for (const sq of searchQueries) {
console.log('[runAgent] Searching Wikipedia for:', sq);
// Try direct page access first
let result = await getWikipediaPage(sq);
if (!result) {
// Fall back to search if direct access fails
const url = await searchWikipedia(sq);
if (url) {
const content = await fetchContent(url);
if (content) {
result = { url, content };
}
}
}
console.log('[runAgent] Result:', result ? 'found' : 'not found');
if (result) {
const title = decodeURIComponent(result.url.split('/').pop() || '');
contextsFull.push({ title, url: result.url, content: result.content });
state.urls = [...state.urls, { query: sq, url: result.url }];
state.contexts = [...state.contexts, { title, url: result.url, chars: result.content.length }];
update();
log(`� Found ${result.url}`);
} else {
log(`⚠️ No result for "${sq}"`);
}
}
if (!state.urls.length) {
log('⚠️ No URLs discovered from the search queries.');
finish('done');
return state;
}
// Content already fetched, skip redundant fetching loop
if (!contextsFull.length) {
log('⚠️ Unable to download content from the discovered links.');
finish('done');
return state;
}
state.embeddingProgress = contextsFull.map(ctx => ({
title: ctx.title.replace(/_/g, ' '),
embeddedChunks: 0,
totalChunks: 0
}));
update();
const embeddedChunks = [];
let pipeline;
try {
pipeline = await similarityPipeline;
} catch (error) {
log('❌ Embedding pipeline unavailable.');
state.error = error.message || 'Embedding pipeline unavailable.';
finish('error');
return state;
}
for (let i = 0; i < contextsFull.length; i += 1) {
const ctx = contextsFull[i];
const pieces = chunkDocument(ctx.content, ctx.title, ctx.url);
state.embeddingProgress[i] = {
...state.embeddingProgress[i],
totalChunks: pieces.length
};
update();
if (!pieces.length) {
log(`⚠️ Context from ${ctx.title} was too short to chunk.`);
continue;
}
// Embed in smaller batches to show progress
const BATCH_SIZE = 5;
for (let batchStart = 0; batchStart < pieces.length; batchStart += BATCH_SIZE) {
const batchEnd = Math.min(batchStart + BATCH_SIZE, pieces.length);
const batchPieces = pieces.slice(batchStart, batchEnd);
const texts = batchPieces.map(piece => piece.text);
try {
const output = await pipeline(texts, { pooling: 'mean', normalize: true });
const embeddingSize = output.dims?.[1] ?? (output.data.length / texts.length);
batchPieces.forEach((piece, idx) => {
const embedding = Array.from(output.data.slice(idx * embeddingSize, (idx + 1) * embeddingSize));
embeddedChunks.push({ ...piece, embedding });
});
state.embeddingProgress[i] = {
...state.embeddingProgress[i],
embeddedChunks: batchEnd
};
update();
} catch (error) {
console.error('Embedding error', error);
log(`❌ Failed to embed batch from ${ctx.title}`);
}
}
log(`🧩 Embedded ${pieces.length} passages from ${ctx.title}`);
}
if (!embeddedChunks.length) {
log('⚠️ No chunks available for retrieval.');
finish('done');
return state;
}
log('🔎 Running vector similarity search...');
const retrieved = await retrieveChunks(query, embeddedChunks, 3);
if (!retrieved.length) {
log('⚠️ No chunk matched the query after retrieval.');
finish('done');
return state;
}
state.retrievedChunks = retrieved.map(({ chunk, similarity }) => ({
title: chunk.title,
url: chunk.url,
similarity,
snippet: extractSnippet(chunk.text),
text: chunk.text,
index: chunk.index
}));
update();
log('🧠 Generating answer from retrieved context...');
const generated = await generateAnswer(query, retrieved);
if (generated.error) {
log(`❌ Answer generation failed: ${generated.answer}`);
state.error = generated.answer;
finish('error');
return state;
}
state.answer = generated.answer;
log('✅ Answer generated successfully.');
finish('done');
return state;
} catch (error) {
console.error('Agent error', error);
state.error = error.message || String(error);
log(`❌ Unexpected error: ${state.error}`);
finish('error');
return state;
}
}
agentTrigger = {
const clicks = runButton ?? 0;
console.log('[agentTrigger] clicks:', clicks, 'lastRunButton:', lastRunButton);
if (clicks !== lastRunButton) {
mutable lastRunButton = clicks;
if (clicks > 0) {
console.log('[agentTrigger] Calling runAgent with query:', queryInput);
runAgent(queryInput).catch(error => {
console.error('[agentTrigger] Agent run failed', error);
});
}
}
return clicks;
}{
const targetDiv = document.querySelector('#agent-demo-output');
// Force dependency on both trigger and state
agentTrigger;
const result = agentState;
try {
const panelStyle = 'background-color: #1e1e1e; color: #d4d4d4; border: 1px solid #3e3e3e; border-radius: 6px; padding: 5px; font-size: 0.75em; line-height: 1.0; margin: 0;';
const headingStyle = 'font-weight: 600; margin-bottom: 8px; color: #79d2ff; text-transform: uppercase; letter-spacing: 0.05em; font-size: 0.85em;';
const statusStyles = {
idle: '#bbb',
running: '#79d2ff',
done: '#3fb618',
error: '#ff8080'
};
const statusLabel = {
running: 'Running',
done: 'Completed',
error: 'Error'
}[result.status] || 'Idle';
const statusColor = statusStyles[result.status] || '#bbb';
const renderProgress = entry => {
if (!entry.totalChunks) {
return html`<div style="margin-bottom: 12px;">
<div style="font-weight: 500; margin-bottom: 4px;">${entry.title}</div>
<div style="font-size: 0.7em; color: #bbb;">No retrievable chunks</div>
</div>`;
}
const percent = Math.round((entry.embeddedChunks / entry.totalChunks) * 100);
return html`<div style="margin-bottom: 12px;">
<div style="display: flex; justify-content: space-between; font-weight: 500; margin-bottom: 4px;">
<span>${entry.title}</span>
<span style="color: #bbb;">${entry.embeddedChunks}/${entry.totalChunks} chunks</span>
</div>
<div style="position: relative; height: 6px; border-radius: 4px; background-color: #2d2d2d; overflow: hidden;">
<div style="width: ${percent}%; background: linear-gradient(90deg, #79d2ff, #1f8fff); height: 100%; border-radius: 4px;"></div>
</div>
</div>`;
};
const renderChunks = chunks => {
if (!chunks.length) {
return html`<div style="color: #bbb; font-size: 0.75em;">No chunks retrieved.</div>`;
}
return html`<div style="display: flex; flex-direction: column; gap: 8px;">
${chunks.map((chunk, idx) => html`<details style="border: 1px solid #3e3e3e; border-radius: 4px; background-color: #111;">
<summary style="list-style: none; cursor: pointer; padding: 10px 12px; font-weight: 500; color: #d4d4d4;">
<span style="color: #79d2ff;">(${idx + 1}) ${chunk.title}</span>
<span style="color: #999; font-size: 0.7em; margin-left: 8px;">${(chunk.similarity * 100).toFixed(1)}%</span>
<div style="margin-top: 6px; font-size: 0.75em; color: #bbb;">${chunk.snippet}</div>
</summary>
<div style="padding: 12px; font-size: 0.75em; color: #bbb; border-top: 1px solid #3e3e3e; white-space: pre-wrap;">${chunk.text}</div>
</details>`)}
</div>`;
};
const leftColumn = html`<div style="display: flex; flex-direction: column; gap: 16px;">
<div style="${panelStyle}">
<div style="${headingStyle}">Run Info</div>
<div style="margin-bottom: 6px;"><span style="font-weight: 600; color: #bbb;">Query:</span> ${result.query || '—'}</div>
<div style="display: inline-flex; align-items: center; gap: 8px; font-size: 0.75em;">
<span style="background: ${statusColor}; color: #0b0b0b; padding: 2px 8px; border-radius: 999px; font-weight: 600; text-transform: uppercase; letter-spacing: 0.05em;">${statusLabel}</span>
${result.error ? html`<span style="color: #ff8080;">${result.error}</span>` : ''}
</div>
</div>
<div style="${panelStyle}">
<div style="${headingStyle}">Search Queries</div>
${result.searchQueries.length ? html`<div style="display: flex; flex-wrap: wrap; gap: 6px;">
${result.searchQueries.map(q => html`<span style="background: #103c92; color: #fff; padding: 4px 8px; border-radius: 12px; font-size: 0.7em;">${q}</span>`)}
</div>` : html`<div style="color: #bbb;">No search queries produced.</div>`}
</div>
<div style="${panelStyle}">
<div style="${headingStyle}">Embedding Progress</div>
${(result.embeddingProgress && result.embeddingProgress.length) ? result.embeddingProgress.map(renderProgress) : html`<div style="color: #bbb;">Embeddings not started.</div>`}
</div>
<div style="${panelStyle}">
<div style="${headingStyle}">Run Log</div>
${result.logs.length ? html`<ul style="margin: 0; padding-left: 16px;">${result.logs.map(entry => html`<li style="margin-bottom: 4px;">${entry}</li>`)} </ul>` : html`<div style="color: #bbb;">Log empty.</div>`}
</div>
</div>`;
const chunkSources = Array.isArray(result.retrievedChunks) ? result.retrievedChunks : [];
const sources = chunkSources.length
? html`<ul style="margin: 0; padding-left: 18px; font-size: 0.75em;">
${Array.from(new Map(chunkSources.map(chunk => [chunk.url, chunk]))).map(([, chunk]) => html`<li><a href="${chunk.url}" target="_blank" style="color: #79d2ff;">${chunk.title}</a></li>`)}
</ul>`
: html`<div style="color: #bbb; font-size: 0.75em;">No supporting sources yet.</div>`;
const answerBody = result.error
? html`<div style="color: #ff8080;">${result.error}</div>`
: (result.answer
? html`<div style="white-space: pre-wrap;">${result.answer}</div>`
: (result.status === 'running'
? html`<div style="color: #bbb;">Working on the answer...</div>`
: html`<div style="color: #bbb;">No answer produced.</div>`));
const rightColumn = html`<div style="display: flex; flex-direction: column; gap: 16px;">
<div style="${panelStyle}; font-size: 0.8em;">
<div style="${headingStyle}">Generated Answer</div>
${answerBody}
<div style="margin-top: 5px;">
<div style="${headingStyle}">Sources</div>
${sources}
</div>
</div>
<div style="${panelStyle};">
<div style="${headingStyle}">Retrieved Chunks</div>
${renderChunks(result.retrievedChunks || [])}
</div>
</div>`;
const output = html`<div style="display: grid; grid-template-columns: minmax(0, 1fr) minmax(0, 1fr); gap: 24px; height: 800px; padding: 12px;">
${leftColumn}
${rightColumn}
</div>`;
targetDiv.innerHTML = '';
targetDiv.appendChild(output);
return html``;
} catch (error) {
console.error('Agent render failed', error, { result });
return html`<div style="background: #3a1313; color: #ffb3b3; padding: 16px; border: 1px solid #ff8080; border-radius: 6px;">
<strong>Rendering failed:</strong> ${error.message || error}
</div>`;
}
}Conclusion
The real question
Are the benefits of using generative AI worth the cost of extra supervision and the additional engineering effort?
The general answer is:

Takeaways
Tip
Use small models or locally deployed models when possible, and only use large models when absolutely necessary.
Important
Never, ever trust LLM outputs without verification.
References
Breiman, Leo. 2001. “Random Forests.” Machine Learning 45: 5–32.
Cortes, Corinna, and Vladimir Vapnik. 1995. “Support-Vector Networks.” Machine Learning 20: 273–97.
Freund, Yoav, and Robert E Schapire. 1997. “A Decision-Theoretic Generalization of on-Line Learning and an Application to Boosting.” Journal of Computer and System Sciences 55 (1): 119–39.
Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. 2016. Deep Learning. MIT press.
Minsky, Marvin, and Seymour Papert. 1969. “An Introduction to Computational Geometry.” Cambridge Tiass., HIT 479 (480): 104.
Rosenblatt, Frank. 1958. “The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain.” Psychological Review 65 (6): 386.
Rumelhart, David E, Geoffrey E Hinton, and Ronald J Williams. 1986. “Learning Representations by Back-Propagating Errors.” Nature 323 (6088): 533–36.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. “Attention Is All You Need.” Advances in Neural Information Processing Systems 30.
![]()
Large Language Models, Myths and RealitiesEnjeux environnementaux et sociétaux du numérique